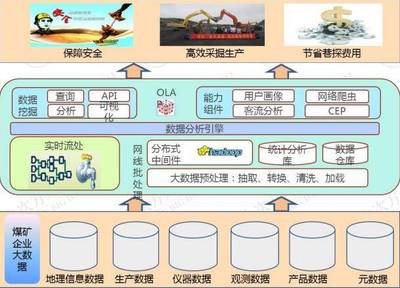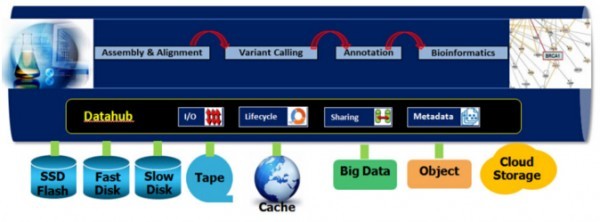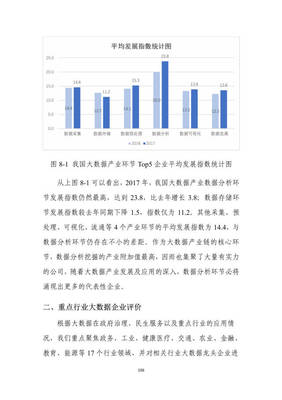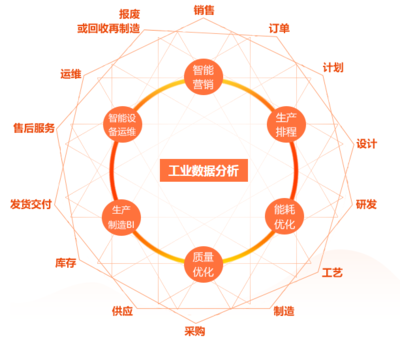
谷歌研究人员发布的一篇新论文在人工智能与计算领域投下了一枚“重磅炸弹”。该论文提出的关键技术,能够将大型语言模型推理过程中占用大量内存的KV Cache压缩高达6倍。这一突破性进展不仅直接影响了相关内存技术公司的股价,更被业界广泛视为可能开启一个类似“DeepSeek时刻”的新纪元,为大数据信息处理服务的效率与可及性带来革命性提升。
一、 核心技术:理解KV Cache与内存瓶颈
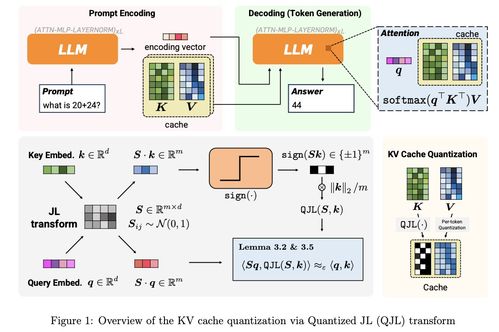
在大型语言模型(如GPT、PaLM等)的推理过程中,为了生成连贯的文本,模型需要记住之前所有生成的token的上下文信息。这部分信息通常以“键-值”(Key-Value,简称KV)对的形式缓存在内存中,称为KV Cache。随着生成长度的增加,KV Cache所占用的内存会线性甚至平方级增长,成为制约模型处理长文本、降低推理成本和提高吞吐量的主要瓶颈。尤其是在需要同时处理大量用户请求的云服务场景下,内存消耗直接关联着硬件成本和能源消耗。
二、 谷歌的突破:6倍压缩如何实现?
谷歌论文的核心在于提出了一种高效、无损或高保真的KV Cache压缩算法。其思路并非简单粗暴地丢弃信息,而是通过创新的方法(可能涉及稀疏化、量化、结构化修剪或动态内存分配等高级技术)来识别并保留对后续生成最关键的那部分上下文信息,同时极大地压缩或高效表示冗余或次要的信息。
关键优势可能包括:
1. 高压缩比:在保证模型输出质量(困惑度)基本不变或仅有极小损失的前提下,实现高达6倍的内存占用减少。
2. 计算友好:压缩与解压过程对计算开销的增加极小,不会显著拖慢推理速度。
3. 即插即用:该方法可能无需对预训练好的模型进行重新训练或微调,可直接应用于现有模型的推理部署中,降低了应用门槛。
三、 市场震动:“内存股价”背后的逻辑
论文成果一经披露,立即在资本市场引发连锁反应,部分内存芯片及存储解决方案供应商的股价应声下跌。这背后的逻辑清晰而直接:
- 需求预期变化:如果未来所有大模型服务提供商都采用此类技术,那么部署相同规模的AI服务所需的内存硬件总量将大幅减少,直接削弱了市场对高端内存(如HBM)长期增长的需求预期。
- 成本结构重塑:AI推理的成本中心可能从昂贵的内存硬件向其他方面转移,改变了产业链的价值分配。
四、 开启“谷歌的DeepSeek时刻”:大数据处理的新范式
“DeepSeek时刻”在此处是一个类比,意指像DeepSeek公司以其高性价比模型引发行业关注一样,谷歌此项技术可能从基础设施层面触发AI应用普及的拐点。
对大数据信息处理服务的影响将是深远的:
- 服务成本大幅降低:云服务商能够以更低的硬件成本提供大模型API服务,最终可能降低企业及开发者的使用门槛。
- 长上下文处理成为常态:内存瓶颈的突破使得模型能够更经济地处理超长文档、长对话历史和多轮分析任务,极大地拓展了在金融分析、法律文档审阅、长篇内容生成等领域的实用边界。
- 实时性与吞吐量飞跃:在固定内存预算下,服务器能够同时处理的用户请求数(吞吐量)显著增加,提升了高并发场景(如智能客服、实时翻译)的服务质量。
- 边缘部署成为可能:压缩后的模型对内存的要求降低,使得在边缘设备(如手机、物联网终端)上运行更强大的模型变得更为可行,推动AI真正走向无处不在。
五、 展望与挑战
尽管前景光明,但该技术走向大规模应用仍需面对一些挑战:压缩算法在不同模型架构和任务上的普适性、极端压缩下输出质量的长期稳定性、以及与现有推理软件栈的集成优化等。这也将促使整个行业更加关注算法创新与硬件协同设计,而不仅仅是追逐参数规模的竞赛。
总而言之,谷歌的这项研究不仅仅是一项技术优化,它更像是一把钥匙,有可能打开高效、普惠AI计算时代的大门。它迫使行业重新审视AI算力的消耗模式,并将加速大数据信息处理服务向更高效、更廉价、更强大的方向演进。未来的AI服务,或许将不再如此“健忘”和“昂贵”,而这正是技术突破带来的最直观的福祉。